Often, I see recommendations for separation, with vague claims about performance improvements. But I assert that the main argument for separation is bureaucratic (license-related), and that separation may well hurt performance. Sure, if you separate the application and the database on separate servers, you gain an easy scale-out effect, but you also end up with a less efficient communication path.
If a database and an application is running on the same operating system instance, you may use very efficient communication channels. With DB2, for example, you may use shared-memory based inter-process communication (IPC) when the application and the database are co-located. If they are on separate servers, TCP must be used. TCP is a nice protocol, offering reliable delivery, congestion control, etc, but it also entails several protocol layers, each contributing overhead.
But let's try to quantify the difference, focusing as closely on the query round-trips as possible.
I wrote a little Java program, LatencyTester, which I used to measure differences between a number of database<>application setups. Java was chosen because it's a compiled, statically typed language; that way, the test-program should have as little internal execution overhead as possible. This can be important: I have sometimes written database benchmark programs in Python (which is a much nicer programming experience), but as Python can be rather inefficient, I ended up benchmarking Python, instead of the database.
The program connects to a DB2 database in one of two ways:
- If you specify a servername and a username, it will communicate using "DRDA" over TCP
- If you leave out servername and username it will use a local, shared memory based channel.
The application issues statements like VALUES(...) where ... is a value set by the application. Note the lack of a SELECT and a FROM in the statement. When invoking the program, you must choose between short or long statements. If you choose short, statements like this will be issued:
VALUES(? + 1)
where ? is a randomly chosen host variable.If you choose long, statements like
VALUES('lksjflkvjw...pvoiwepwvk')
will be issued, where lksjflkvjw...pvoiwepwvk is a 2000-character pseudo-randomly composed string.In other words: The program may run in a mode where very short or very long units are sent back and forth between the application and the database. The short queries are effectively measuring latency, while the long queries may be viewed as measuring throughput.
I used the program to benchmark four different setups:
- Application and database on the same server, using a local connection
- Application and database on the same server, using a TCP connection
- Application on a virtual server hosted by the same server as the database, using TCP
- Application and database on different physical servers, but on the same local area network (LAN), using TCP
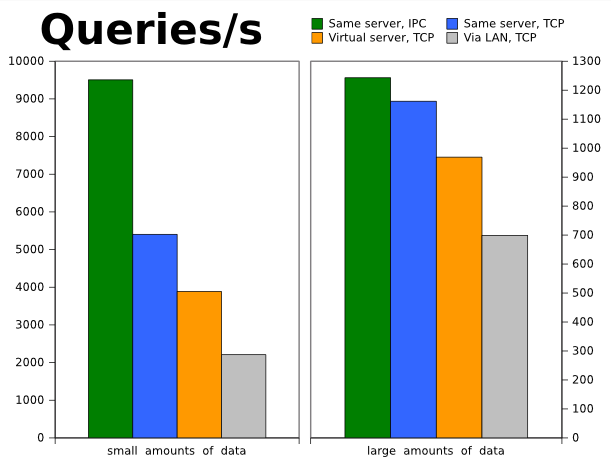
Click on figure to enlarge; opens in new window
Clearly, the the highest number of queries per second is seen when the database and the application are co-located. This is especially true for the short queries: Here, more than four times as many queries may be executed per second when co-locating on the same server, compared to separating over a LAN. When using TCP on the same server, short-query round-trips run at around half the speed.
The results need to be put in perspective, though: While there are clear differences, the absolute numbers may not matter much in the Real World. The average query-time for short local queries were 0.1ms, compared to 0.8ms for short queries over the LAN. Let's assume that we are dealing with a web application where each page-view results in ten short queries. In this case, the round-trip overhead for a location connection is 10x0.1ms=1ms, whereas round-trip overhead for the LAN-connected setup is 10x0.8ms=8ms. Other factors (like query disk-I/O, and browser-to-server roundtrips) will most likely dominate, and the user will hardly notice a difference.
Even though queries over a LAN will normally not be noticeably slower, LANs may sometimes exhibit congestion. And all else being equal, the more servers and the more equipment being involved, the more things can go wrong.
Having established that application/database server-separation will not improve query performance (neither latency, nor throughput), what other factors are involved in the decision between co-location and separation?
- Software licensing terms may make it cheaper to put the database on its own, dedicated hardware: The less CPUs beneath on the database system, the less licensing costs. The same goes for the application server: If it is priced per CPU, it may be very expensive to pay for CPUs which are primarily used for other parts of the solution.
- Organizational aspects may dictate that the the DBA and the application server administrator each have their "own boxes". Or conversely, the organization may put an effort into operating as few servers as possible to keep administration work down.
- The optimal operating system for the database may not be the optimal operating system for the application server.
- The database server may need to run on hardware with special, high-performance storage system attachments. - While the application server (which probably doesn't perform much disk I/O) may be better off running in a virtual server, taking advantage of the flexible administration advantages of virtualization.
- Buying one very powerful piece of server hardware is sometimes more expensive than buying two servers which add up to the same horsepower. But it may also be the other way around, especially if cooling, electricity, service agreements, and rack space is taken into account.
- Handling authentication and group memberships may be easier when there is only one server. E.g., DB2 and PostgreSQL allows the operating system to handle authentication if an application connects locally, meaning that no authentication configuration needs to be set up in the application. (Don't you just hate it when passwords sneak into the version control system?)
- A mis-behaving (e.g. memory leaking) application may disturb the database if the two are running on the same system. Operating systems generally provide mechanisms for resource-constraining processes, but that can often be tricky to setup.
| Pro separation | Con separation |
| Misbehaving application will not be able to disturb the database as much. | Slightly higher latency. |
| May provide for more tailored installations (the database gets its perfect environment, and so does the application). | Less predictable connections on shared networks. |
| If the application server is split into two servers in combination with a load balancing system, each application server may be patched individually without affecting the database server, and with little of no visible down-time for the users. | More hardware/software/systems to maintain, monitor, backup, and document. |
| May save large amounts of money if the database and/or the application is CPU-licensed. | Potentially more base software licensing fees (operating systems, supporting software). |
| Potentially cheaper to buy two modest servers than to buy one top-of-the-market server. | Potentially more expensive to buy two servers if cooling and electricity is taken into account. |
| Allows for advanced scale-out/application-clustering scenarios. | Prevents easy packaging of a complete database+application product, such as a turn-key solution in a single VMWare or Amazon EC2 image. |
Is the situation markedly different with other DBMSes?